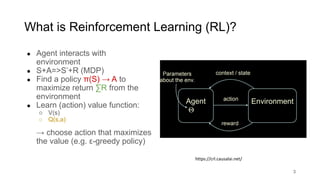
RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 02 junho 2024

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.

deep learning – Severely Theoretical
Tags

Mastering Atari Games with Limited Data – arXiv Vanity

deep learning – Severely Theoretical
Aman's AI Journal • Papers List
2008.06495] Joint Policy Search for Multi-agent Collaboration with Imperfect Information
RL Weekly 37: Observational Overfitting, Hindsight Credit Assignment, and Procedurally Generated Environment Suite

State of AI Report 2023 - Air Street Capital

Scheduling UAV Swarm with Attention-based Graph Reinforcement Learning for Ground-to-air Heterogeneous Data Communication

Atari 2600 Kangaroo Benchmark (Atari Games)
Memory for Lean Reinforcement Learning.pdf

PDF) Mastering Atari Games with Limited Data
Warm-start Reinforcement Learning Mobility Science Automation and Inclusion Center

Superhuman Performance on the Atari 100K Benchmark: The Power of BBF - A New Value-Based RL Agent from Google DeepMind, Mila, and Universite de Montreal - MarkTechPost
Recomendado para você
-
 AlphaZero on Carlsen-Caruana Games 1-802 junho 2024
AlphaZero on Carlsen-Caruana Games 1-802 junho 2024 -
ZeroBias: A Lesson from AlphaZero02 junho 2024
-
 AlphaZero - Wikipedia02 junho 2024
AlphaZero - Wikipedia02 junho 2024 -
 One Giant Step for a Chess-Playing Machine - The New York Times02 junho 2024
One Giant Step for a Chess-Playing Machine - The New York Times02 junho 2024 -
 AlphaZero Chess Engine: The Ultimate Guide02 junho 2024
AlphaZero Chess Engine: The Ultimate Guide02 junho 2024 -
 AI learns to rule the quantum world02 junho 2024
AI learns to rule the quantum world02 junho 2024 -
 Alpha Zero and Monte Carlo Tree Search02 junho 2024
Alpha Zero and Monte Carlo Tree Search02 junho 2024 -
 How the Artificial Intelligence Program AlphaZero Mastered Its02 junho 2024
How the Artificial Intelligence Program AlphaZero Mastered Its02 junho 2024 -
 AlphaZero Chess: How It Works, What Sets It Apart, and What It Can02 junho 2024
AlphaZero Chess: How It Works, What Sets It Apart, and What It Can02 junho 2024 -
 Machine Learning for Chess — AlphaZero vs Stockfish02 junho 2024
Machine Learning for Chess — AlphaZero vs Stockfish02 junho 2024

você pode gostar
-
 Five Nights at Freddy's: Security Breach (Build 11744860 + Ruin02 junho 2024
Five Nights at Freddy's: Security Breach (Build 11744860 + Ruin02 junho 2024 -
 Plants Vs. Zombies Cute Pendulum 2 Twin Sunflower Sun Flower Spring Children's Toy Decoration Car Accessories - Fantasy Figurines - AliExpress02 junho 2024
Plants Vs. Zombies Cute Pendulum 2 Twin Sunflower Sun Flower Spring Children's Toy Decoration Car Accessories - Fantasy Figurines - AliExpress02 junho 2024 -
 NCERT Solutions Class 4 EVS Chapter 1 Going To School - Free Download02 junho 2024
NCERT Solutions Class 4 EVS Chapter 1 Going To School - Free Download02 junho 2024 -
 4.bp.blogspot.com/-S4-aJRMpud4/W6EZ2UQ6-2I/AAAAAAA02 junho 2024
4.bp.blogspot.com/-S4-aJRMpud4/W6EZ2UQ6-2I/AAAAAAA02 junho 2024 -
 IMDb's Top 10 Highest-rated Movies on Streaming Right Now02 junho 2024
IMDb's Top 10 Highest-rated Movies on Streaming Right Now02 junho 2024 -
 3d lâmpada jogo configuração rifle arma padrões led night light gamer decoração candeeiro de mesa cs game room decoração meninos meninas presente02 junho 2024
3d lâmpada jogo configuração rifle arma padrões led night light gamer decoração candeeiro de mesa cs game room decoração meninos meninas presente02 junho 2024 -
 Francois-Edouard Bertin Oil Painting Reproductions for Sale02 junho 2024
Francois-Edouard Bertin Oil Painting Reproductions for Sale02 junho 2024 -
Ahmed Abdullah (@N_S_03) / X02 junho 2024
-
 Assistir Hajime no Ippo: New Challenger - Episódio 008 Online em HD - AnimesROLL02 junho 2024
Assistir Hajime no Ippo: New Challenger - Episódio 008 Online em HD - AnimesROLL02 junho 2024 -
 PS3 - webMan Classics Maker: Launch ISOs straight from XMB02 junho 2024
PS3 - webMan Classics Maker: Launch ISOs straight from XMB02 junho 2024
