Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play
Por um escritor misterioso
Last updated 02 junho 2024
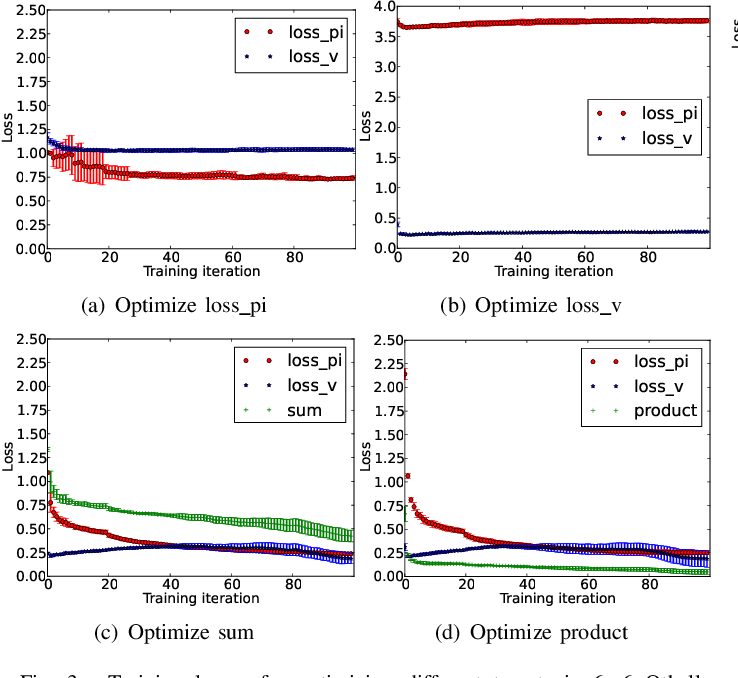
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.
The Evolution of AlphaGo to MuZero, by Connor Shorten
AlphaZero Explained · On AI

A general reinforcement learning algorithm that masters chess
AlphaDDA: strategies for adjusting the playing strength of a fully
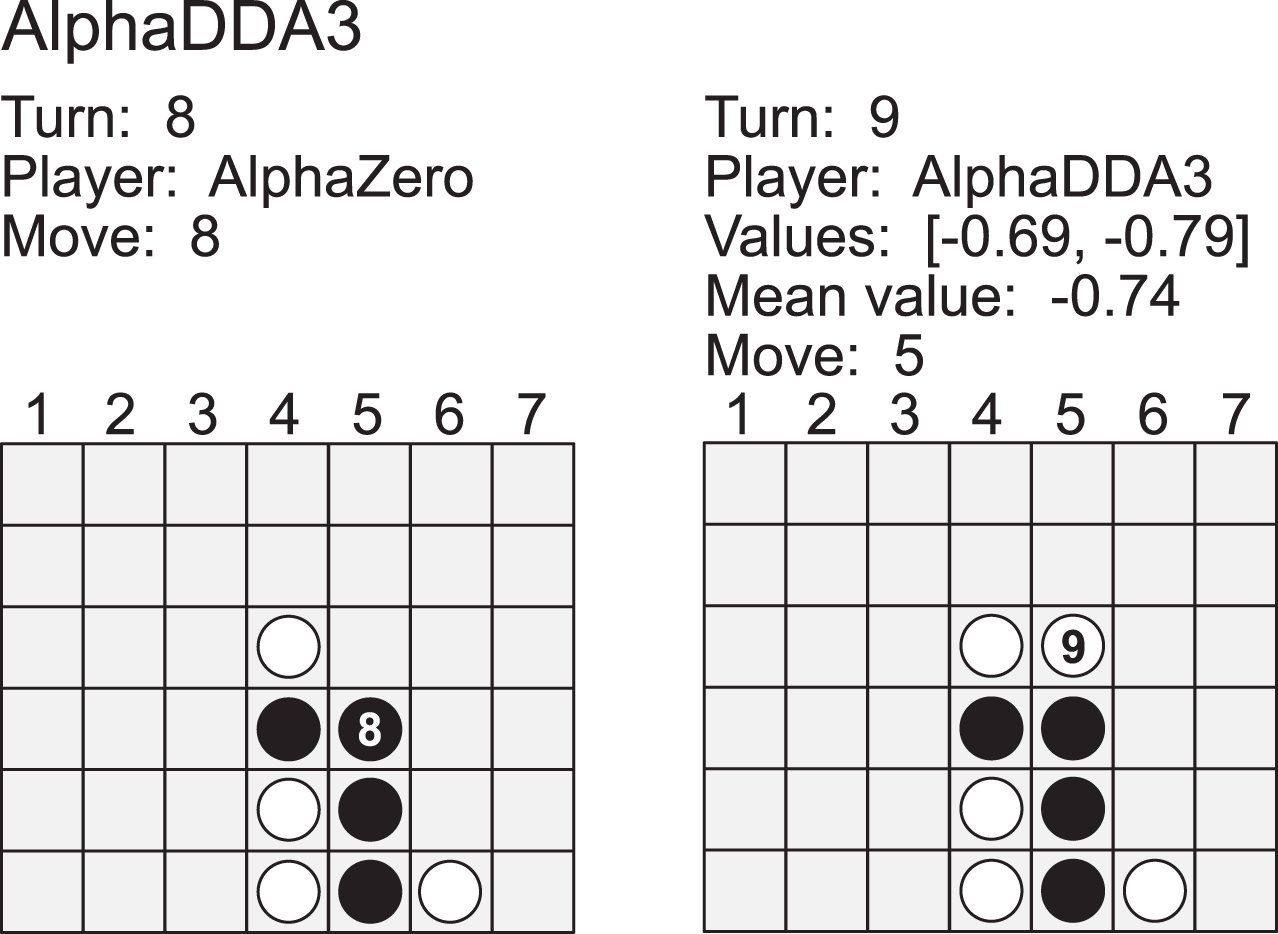
AlphaDDA: strategies for adjusting the playing strength of a fully

Representation Matters: The Game of Chess Poses a Challenge to

Representation Matters: The Game of Chess Poses a Challenge to

PDF) Expediting Self-Play Learning in AlphaZero-Style Game-Playing
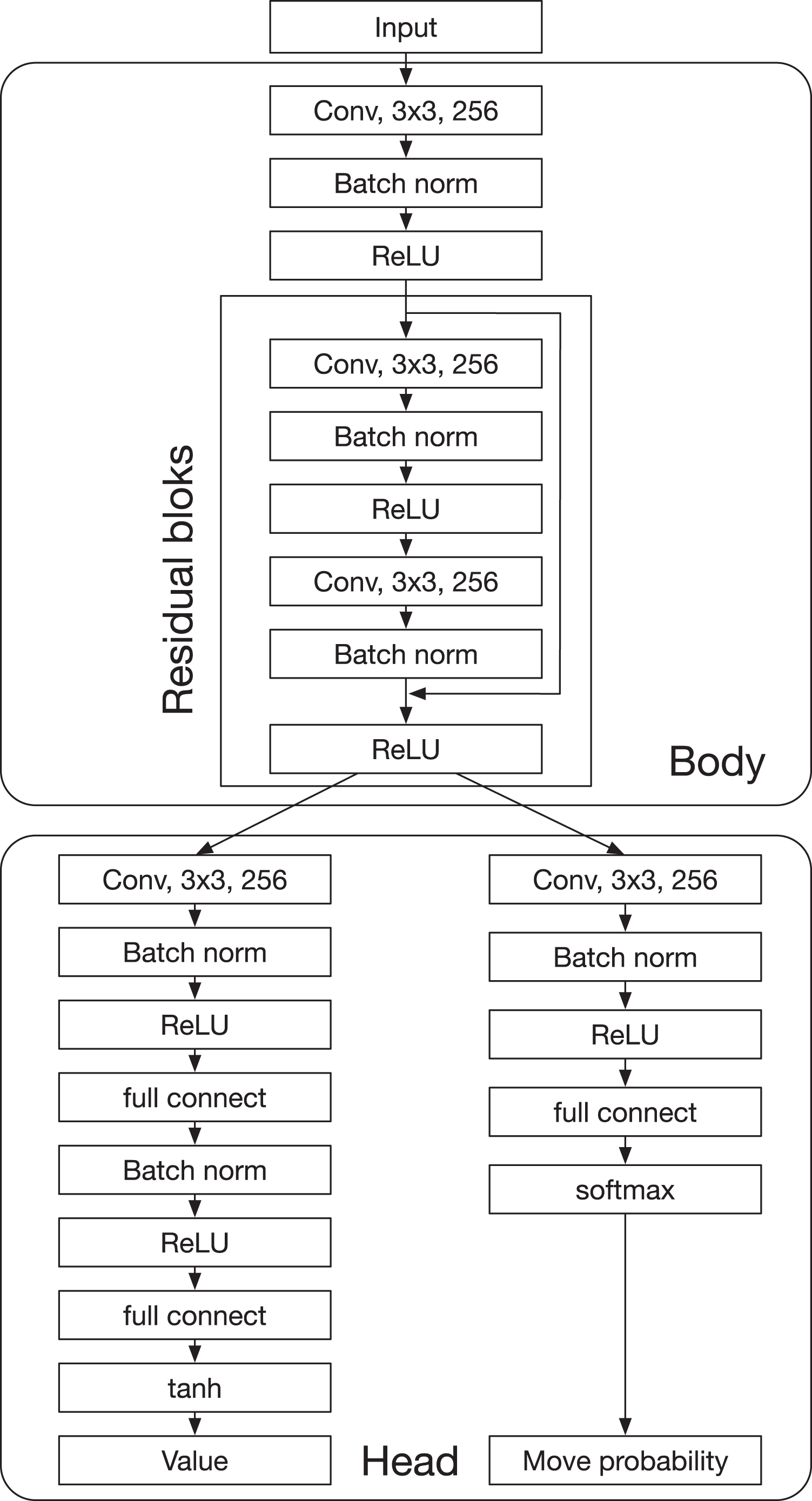
AlphaDDA: strategies for adjusting the playing strength of a fully

Reimagining Chess with AlphaZero, February 2022

Policy or Value ? Loss Function and Playing Strength in AlphaZero
Recomendado para você
-
 AlphaZero - Wikipedia02 junho 2024
AlphaZero - Wikipedia02 junho 2024 -
 Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos02 junho 2024
Revista de Xadrez New In Chess 2019-8 Magnus Carlsen Observe as Fotos02 junho 2024 -
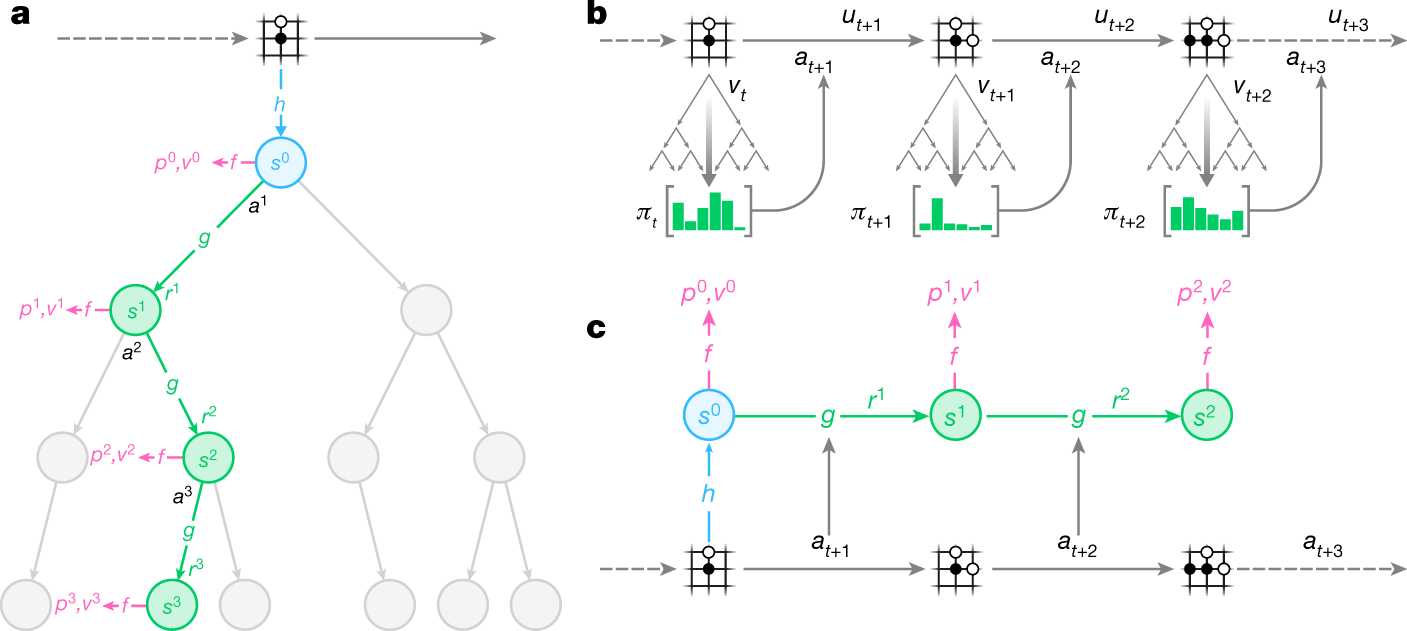 Mastering Atari, Go, chess and shogi by planning with a learned model02 junho 2024
Mastering Atari, Go, chess and shogi by planning with a learned model02 junho 2024 -
 Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess Forums - Page 1502 junho 2024
Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess Forums - Page 1502 junho 2024 -
 STREET FIGHTER ALPHA ZERO KEN ANIME PRODUCTION CEL 402 junho 2024
STREET FIGHTER ALPHA ZERO KEN ANIME PRODUCTION CEL 402 junho 2024 -
 Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop02 junho 2024
Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop02 junho 2024 -
 Free Course: DeepMind's AlphaGo Zero and AlphaZero, RL paper explained from Aleksa Gordić - The AI Epiphany02 junho 2024
Free Course: DeepMind's AlphaGo Zero and AlphaZero, RL paper explained from Aleksa Gordić - The AI Epiphany02 junho 2024 -
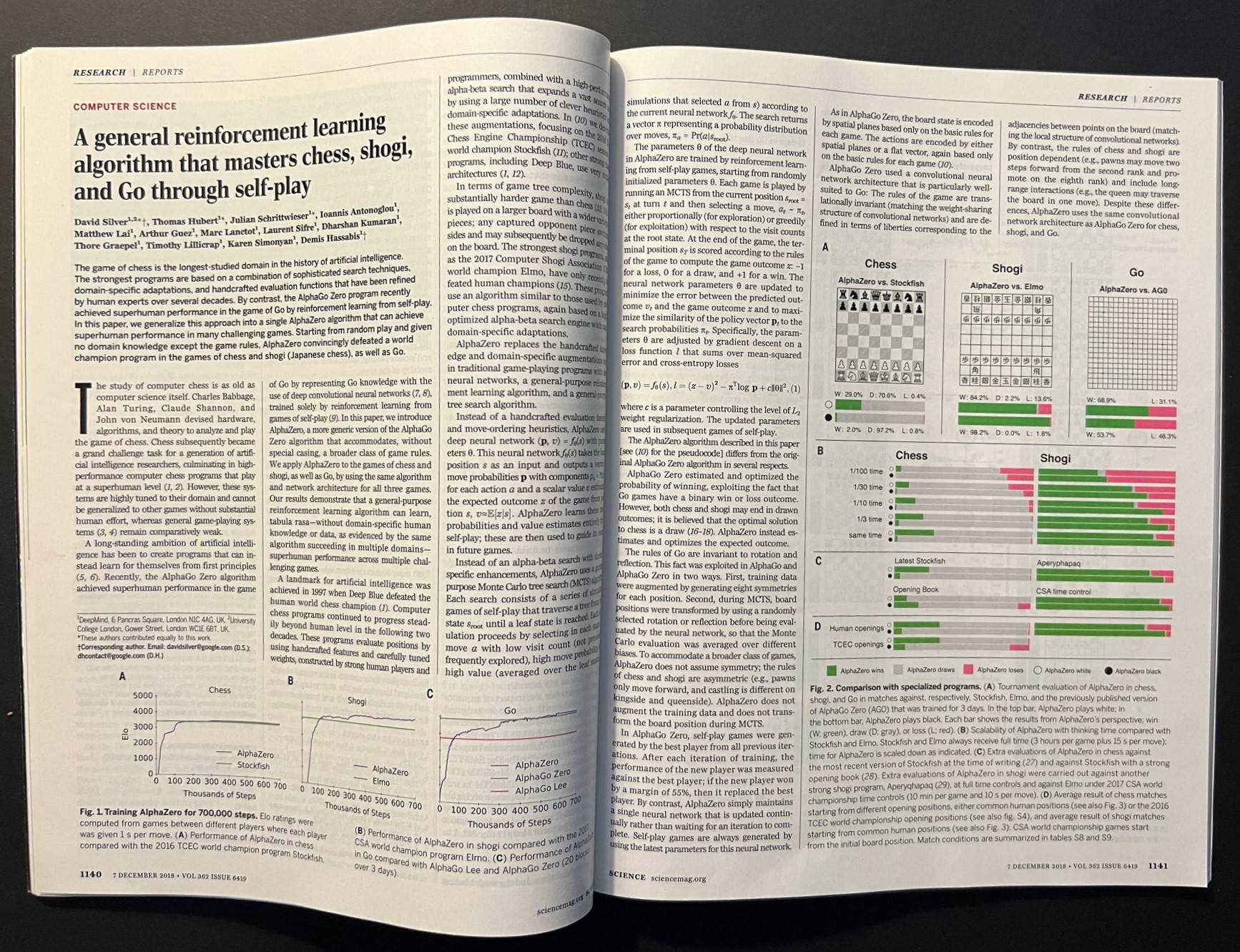 David Silver (et al.), A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. With: Garry Kasparov, Chess, a Drosophila of Reasoning. And with: Murray Campbell, Mastering Board games02 junho 2024
David Silver (et al.), A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. With: Garry Kasparov, Chess, a Drosophila of Reasoning. And with: Murray Campbell, Mastering Board games02 junho 2024 -
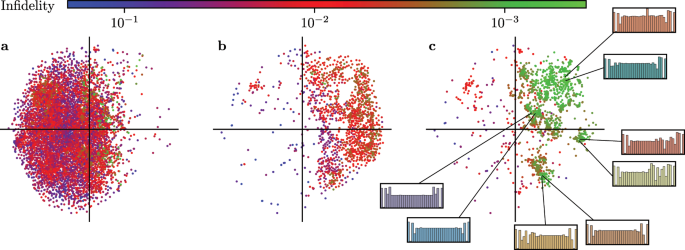 Global optimization of quantum dynamics with AlphaZero deep exploration02 junho 2024
Global optimization of quantum dynamics with AlphaZero deep exploration02 junho 2024 -
 Move over AlphaGo: AlphaZero taught itself to play three different02 junho 2024
Move over AlphaGo: AlphaZero taught itself to play three different02 junho 2024
você pode gostar
-
 24 Miklos Dudas Photos & High Res Pictures - Getty Images02 junho 2024
24 Miklos Dudas Photos & High Res Pictures - Getty Images02 junho 2024 -
 Isekai Meikyuu de Harem wo - Episódios - Saikô Animes02 junho 2024
Isekai Meikyuu de Harem wo - Episódios - Saikô Animes02 junho 2024 -
 The Dungeon of Black Company Season 2: Renewal Status, Plot Release Date02 junho 2024
The Dungeon of Black Company Season 2: Renewal Status, Plot Release Date02 junho 2024 -
 JOGO DE TERROR PRA CELULAR! FUGINDO DA CASA DA VELHA! GRANNY!02 junho 2024
JOGO DE TERROR PRA CELULAR! FUGINDO DA CASA DA VELHA! GRANNY!02 junho 2024 -
 Regresso à vista para Rafael Nadal: Open da Austrália confirma que02 junho 2024
Regresso à vista para Rafael Nadal: Open da Austrália confirma que02 junho 2024 -
 Got the Dream Zeri ARAM Game : r/ARAM02 junho 2024
Got the Dream Zeri ARAM Game : r/ARAM02 junho 2024 -
 Palavra do autor - Caçadores de Criptídeos RPG (PT-BR) by Ingo Muller02 junho 2024
Palavra do autor - Caçadores de Criptídeos RPG (PT-BR) by Ingo Muller02 junho 2024 -
 Project Playtime Android by Firugamer Studio - Game Jolt02 junho 2024
Project Playtime Android by Firugamer Studio - Game Jolt02 junho 2024 -
 Lucemon: Falldown Mode - Wikimon - The #1 Digimon wiki02 junho 2024
Lucemon: Falldown Mode - Wikimon - The #1 Digimon wiki02 junho 2024 -
 Kami-tachi ni Hirowareta Otoko Dublado 12 Final Online02 junho 2024
Kami-tachi ni Hirowareta Otoko Dublado 12 Final Online02 junho 2024